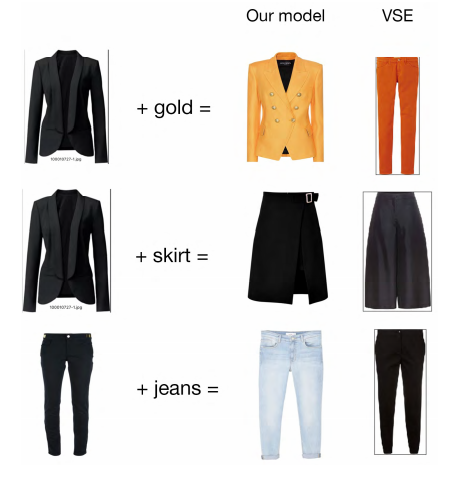
 Example results obtained with DeepStyle
Example results obtained with DeepStyle
Abstract
In this paper, we propose a multimodal search engine that combines visual and textual cues to retrieve items from a multimedia database aesthetically similar to the query. The goal of our engine is to enable intuitive retrieval of fashion merchandise such as clothes or furniture. Existing search engines treat textual input only as an additional source of information about the query image and do not correspond to the real-life scenario, where the user looks for “the same shirt but of denim”. Our novel method, dubbed DeepStyle, mitigates those shortcomings by using a joint neural network architecture to model contextual dependencies between features of different modalities. We prove the robustness of this approach on two different challenging datasets of fashion items and furniture where our DeepStyle engine outperforms baseline methods by more than 20% on tested datasets. Our search engine is commercially deployed and available through a Web-based application.