Using Random Forest Classifier for particle identification in the ALICE Experiment
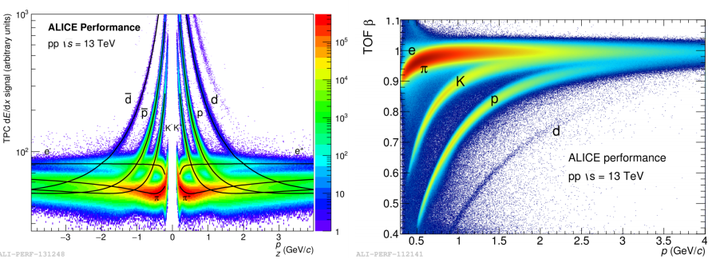 Results of the measurements of (left) the energy loss in the TPC with lines corresponding to Bethe-Block parametrisation and (right) particle’s velocity $\beta$ in the TOF detector as a function of particle’s momentu
Results of the measurements of (left) the energy loss in the TPC with lines corresponding to Bethe-Block parametrisation and (right) particle’s velocity $\beta$ in the TOF detector as a function of particle’s momentu
Abstract
Particle identification is very often crucial for providing high quality results in high-energy physics experiments. A proper selection of an accurate subset of particle tracks containing particles of interest for a given analysis requires filtering out the data using appropriate threshold parameters. Those parameters are typically chosen sub-optimally by using the so-called “cuts” – sets of simple linear classifiers that are based on well-known physical parameters of registered tracks. Those classifiers are fast, but they are not robust to various conditions which can often result in lower accuracy, efficiency, or purity in identifying the appropriate particles. Our results show that by using more track parameters than in the standard way, we can create classifiers based on machine learning algorithms that are able to discriminate much more particles correctly while reducing traditional method’s error rates. More precisely, we see that by using a standard Random Forest method our approach can already surpass classical methods of cutting tracks.