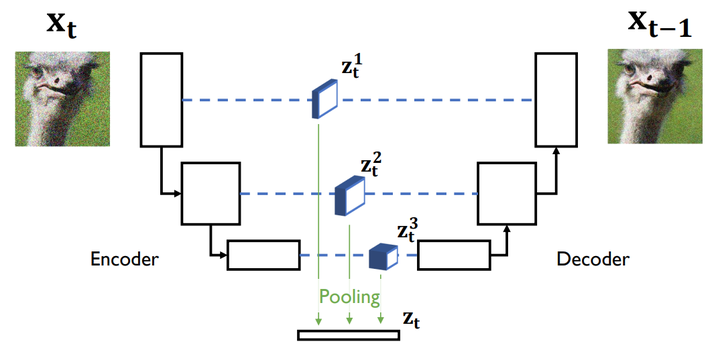
 Data representation $z_t$ in a UNet-based diffusion model.
Data representation $z_t$ in a UNet-based diffusion model.
Abstract
Joint machine learning models that allow synthesizing and classifying data often offer uneven performance between those tasks or are unstable to train. In this work, we depart from a set of empirical observations that indicate the usefulness of internal representations built by contemporary deep diffusion-based generative models not only for generating but also predicting. We then propose to extend the vanilla diffusion model with a classifier that allows for stable joint end-to-end training with shared parameterization between those objectives. The resulting joint diffusion model outperforms recent state-of-the-art hybrid methods in terms of both classification and generation quality on all evaluated benchmarks. On top of our joint training approach, we present how we can directly benefit from shared generative and discriminative representations by introducing a method for visual counterfactual explanations.