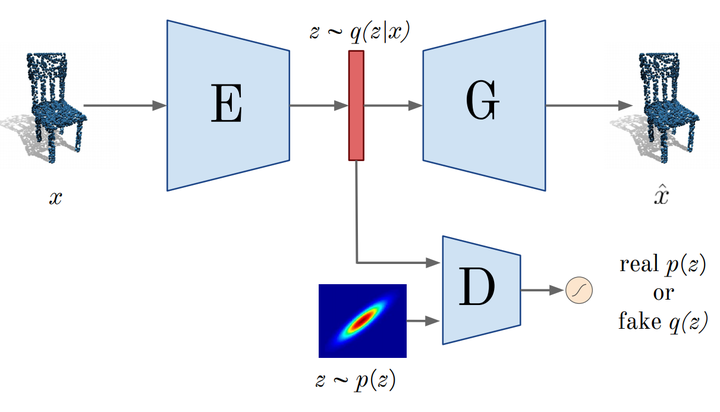
 Pipeline of our 3D-AAE for point clouds
Pipeline of our 3D-AAE for point clouds
Abstract
Deep generative architectures provide a way to model not only images but also complex, 3-dimensional objects, such as point clouds. In this work, we present a novel method to obtain meaningful representations of 3D shapes that can be used for challenging tasks including 3D points generation, reconstruction, compression, and clustering. Contrary to existing methods for 3D point cloud generation that train separate decoupled models for representation learning and generation, our approach is the first end-to-end solution that allows to simultaneously learn a latent space of representation and generate 3D shape out of it. Moreover, our model is capable of learning meaningful compact binary descriptors with adversarial training conducted on a latent space. To achieve this goal, we extend a deep Adversarial Autoencoder model (AAE) to accept 3D input and create 3D output. Thanks to our end-to-end training regime, the resulting method called 3D Adversarial Autoencoder (3dAAE) obtains either binary or continuous latent space that covers a much wider portion of training data distribution. Finally, our quantitative evaluation shows that 3dAAE provides state-of-the-art results for 3D points clustering and 3D object retrieval.